Technology
Content Ownership Rights in the AI Era
Arkansas has begun defining who owns AI-generated content, but unresolved copyright disputes over training data and AI outputs will shape how far those ownership rights can go.

As the AI revolution rapidly transforms society, the U.S. legal system is scrambling to answer a foundational question: Who owns AI-generated content? The rate at which society has adopted generative AI is unparalleled. According to the Stanford HAI 2026 AI Index Report, generative AI reached approximately 53% population-level adoption within its first three years, faster than either the personal computer or the internet.[1]
Given its rapid adoption, most governmental bodies have yet to clearly define the scope and limits of ownership rights in AI-generated output. The Arkansas General Assembly sought to address this issue through the adoption of Act 927 of 2025. The law provides that “the person who provides the input or directive to the generative artificial intelligence tool shall be the owner of the generated content, provided that the content does not infringe on existing copyrights or intellectual property rights.”[2]
This poses a broader question: How will copyright law adapt to an AI-driven world? As the figure below illustrates, courts across the country are now grappling with that question.
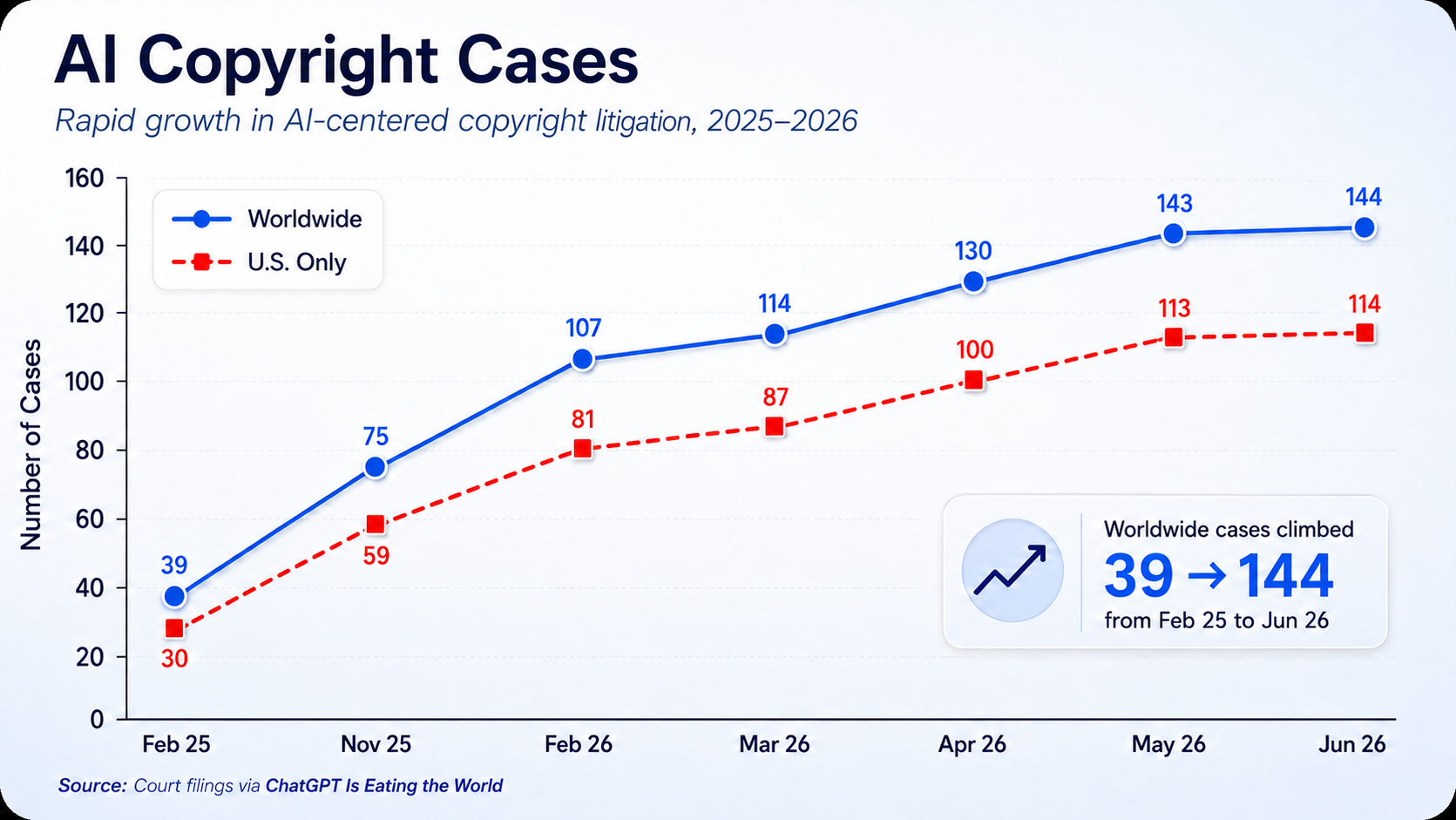
Figure 1. Growth of AI copyright litigation. Graphic by Arkansas Emerging Issues; based on cited court filings and legal authorities.
So far, courts have used a holistic approach that carefully balances preservation of fair use and protection of intellectual property rights. These cases generally involve one or both of two categories of claims: input infringement and output infringement.
Input And Output Infringement
To develop generative AI models, companies must train them on enormous amounts of data. A recent review estimates that GPT-4 was trained on roughly 13 trillion tokens.[3] The following infographic puts that scale into perspective.

Figure 2. What 13 trillion tokens look like. Graphic by Arkansas Emerging Issues; calculations based on cited sources.
Much of this training content comes from public sources. Project Gutenberg, for example, offers more than 75,000 free public domain eBooks. Public coding forums and open web material also provided vital data during early AI development. However, as AI models grew more sophisticated, the demand for newer, copyrighted material increased.
The use of copyrighted material to train models led to a rapid increase in copyright disputes. While AI companies have not disputed their use of these copyrighted materials, the key question is whether their use of these materials is legally protected by the fair use doctrine.
In addition, Plaintiffs in recent cases have alleged that AI models have substantially reproduced their copyrighted materials. This form of infringement, known as output infringement, could potentially dilute the market for the original creator’s work and threaten their revenue stream.
Fair Use and Training Data
The tech giant Meta initially explored licensing books for training, but the ownership of those works was fragmented and large-scale licensing was impractical. Plaintiffs in Kadrey v. Meta Platforms, Inc. alleged that Meta instead used online “shadow libraries” to obtain copyrighted books to train its Llama models.[4]
While the ethical implications of using shadow libraries have been widely debated, input infringement cases rest primarily on a doctrine formed from a 185-year-old opinion established in Folsom v. Marsh. The case concerned the piracy of letters drafted by George Washington. In his opinion, Justice Joseph Story developed a balance test that carefully considered factors such as the nature of the new work, significance of the portion of the work copied, and the effect on the market value of the original work. This balance test forms the foundation of the modern fair use doctrine codified in the Copyright Act of 1976.[5]
AI companies have heavily used the fair use doctrine to defend copyright infringement claims because it provides heightened protections for works that have a transformative purpose and do not cause meaningful harm to the original creator.
Federal judges have recently sided with AI companies on claims that generate AI model training is transformative.
In Bartz v. Anthropic PBC, Judge William Alsup analogized market dilution claims from AI generated literary content to a claim that “training schoolchildren to write well would create more competing works.”[6]
The analogy used by Judge Alsup is certainly thought provoking. Consider the literary great Charles Dickens. His vivid and often bizarre characterizations were a hallmark of his literary style, but that style was heavily influenced by earlier novelists such as Tobias Smollett and Henry Fielding. Does AI ingestion of copyrighted content differ from Dickens use of prior literary works?
One answer comes from Judge Vince Chhabria’s opinion in Kadrey. Judge Chhabria emphasized that the primary goal of copyright law is to preserve the incentive for human beings to create original works.[7]

Figure 3. Adapted pull quote from Judge Vince Chhabria, Kadrey v. Meta Platforms, Inc. (N.D. Cal. 2025). Graphic by Arkansas Emerging Issues.
The distinction between human beings and AI is critical. While human beings can absorb the style and substance of prior literary works, AI is able to memorize and regurgitate large portions of copyrighted material verbatim. This ability has led to increasing concerns of market dilution and economic harm to content creators.
In response, large AI companies have adopted guardrails to reduce verbatim reproduction, but plaintiffs in multiple cases have alleged that those guardrails are often incomplete or easily bypassed.
The Kadrey Lesson
Kadrey featured 13 prominent authors, including Richard Kadrey, Sarah Silverman, and Christopher Golden, who claimed that Meta illegally copied their works to train its Llama models.
In this case, the Plaintiffs claims of output infringement were largely unfounded. Experts from both sides were unable to show that Llama could regurgitate more than 50 words from any plaintiff’s book[8]. The Plaintiff’s also claimed that AI generated books were flooding Amazon’s online marketplace. However, they were unable to show that the introduction of these books meaningfully diluted the market for human generated content[9].
Despite these findings, Judge Chabbria warned that AI could potentially dilute creative markets and crowd out lesser-known writers. As the figure below illustrates, a study of over 10 million Amazon kindle e-books revealed the rapid proliferation of AI generated content[10].
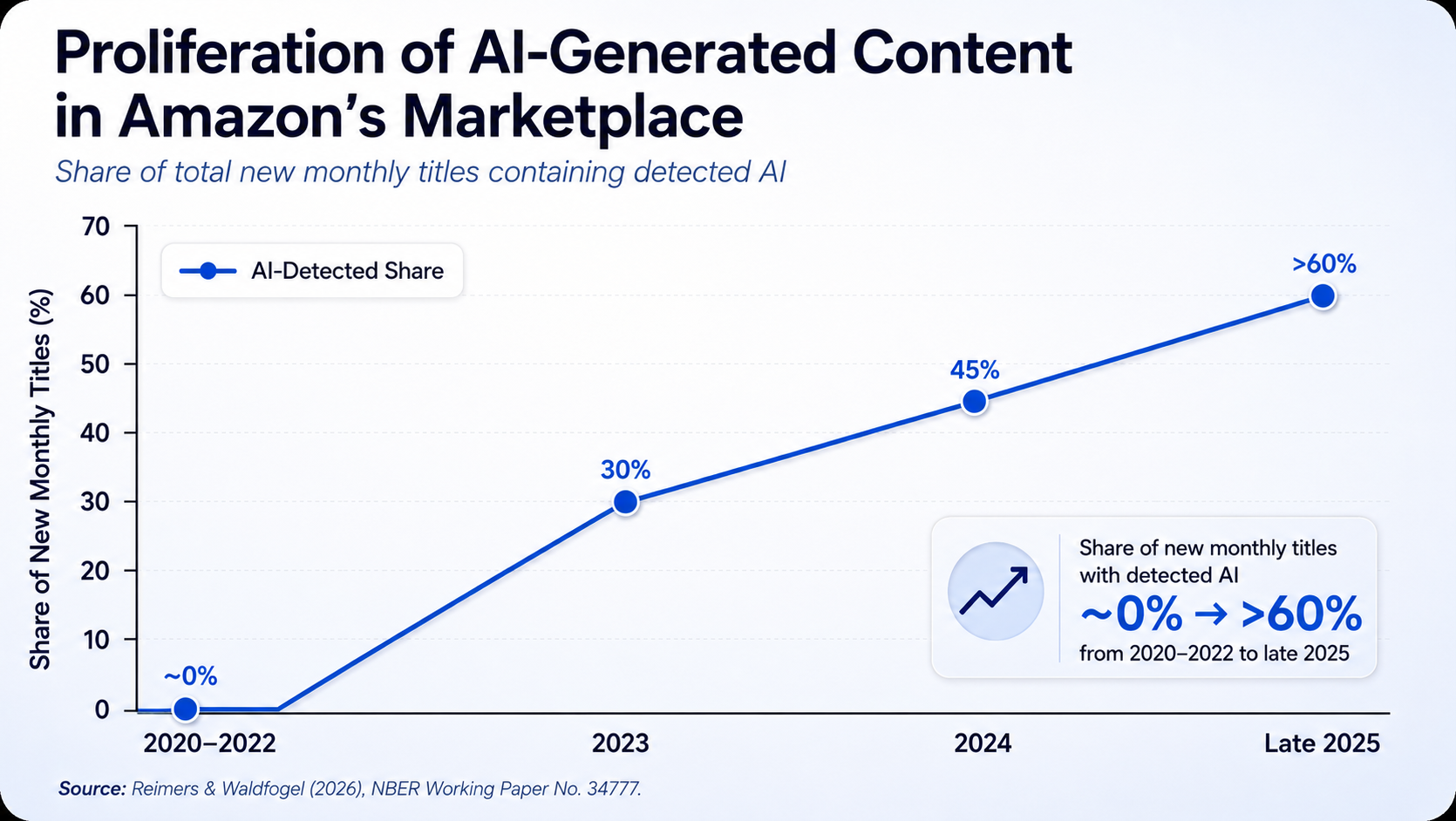
Figure 4. Share of new Amazon Kindle titles containing detected AI-generated content, 2020–2025. Graphic by Arkansas Emerging Issues; based on Reimers & Waldfogel (2026), NBER Working Paper No. 34777.
Despite the massive influx of these books, the study notes that, “the average quality of new books has fallen with the LLM-induced influx, and books with detected AI are substantially worse than human-authored books, so that much of the new work is of little value to consumers.” Despite the lower quality and value of AI-generated books, LLM’s have actually increased consumer surplus in the book market by 7%[11].
The greater concern for content creators is whether regurgitation of their copyrighted content is partially response for this rapid growth.
Why Output Matters
While the fair use doctrine often protects the use of works for transformative purposes, AI developers are still responsible for ensuring that copyrighted material is not inadvertently distributed to users.
Despite the potential for harm to content creators, output infringement claims have yet to gain significant traction in federal courts.
In Andersen v. Stability AI, output-based infringement claims against Stability AI, were dismissed. These claims were based in part on theories of secondary liability, including vicarious liability, which would allow content creators to hold AI developers liable for the actions of their users. However, As Judge William Orrick noted, these claims are dependent upon an act of direct infringement[12]. Thus, the plaintiffs must prove that the AI-generated outputs are substantially similar to the protected expression in the original work. While the visual test is not the only factor in determining substantial similarity, the following images show the how Andersen’s original work compares to the image generated by Stability AI[13].


Figure 5. Comparison of Sarah Andersen’s original artwork and an AI-generated image cited in Andersen v. Stability AI Ltd.. Sources: Sarah Andersen and the cited legal authorities.
Recent output infringement cases raise an interesting question: Will courts continue to apply traditional substantial similarity principles despite generative AI’s ability to clone an artist’s style, an unprotected element, without replicating the copyrighted work? If AI generated work could serve as a close substitute for the artists work in the marketplace, the resulting market dilution could be just as damaging to the artists revenue stream.
The music industry is especially vulnerable to output infringement. In Poseidon Wave Media LLC v. Suno, Inc., the plaintiff alleged that it tested an AI model developed by Suno and was able to closely match its 236 copyrighted sound recordings Suno had ingested during training.[14] Furthermore, the plaintiff alleged that its licensing revenue had fallen by nearly 80% since the launch of Suno’s AI model.[15] If the plaintiff is successful, this case could provide an avenue for other music producers and artists to protect their copyrighted sound recordings.
News publishers have also alleged output infringement. In Dow Jones & Co. v. Perplexity AI, Inc., the Plaintiffs alleged that Perplexity’s answer engine lets users “Skip the Links” to original publishers and receive summaries instead. The Plaintiffs further alleged that Perplexity built the database supplying its answer engine by copying online news content on a massive scale.[16] The introduction of AI search tools such as Perplexity and Google AI mode are projected to significantly impact the publishing industry. According to Marc McCollum, executive vice president of innovation at Raptive, ad revenue loss attributable to Google generative AI could amount to as much as $2 billion annually across the publishing industry.[17] Google has defended these claims by stating in part that its generative AI models encourage users to ask deeper, more complex questions and this leads to more chances for publisher links to be clicked[18].
The Copyright Paradox

Figure 6. Adapted pull quote from Judge Beryl A. Howell, Thaler v. Perlmutter (D.D.C. 2023). Graphic by Arkansas Emerging Issues.
Despite the rapid growth in novel AI-generated content, the copyrightability of these works remains complex. In Thaler v. Perlmutter, the U.S. District Court for the District of Columbia denied copyright registration for an image generated entirely by AI[19]. However, as Supreme Court Justice Sandra Day O’Connor stated in Feist Publications, Inc. v. Rural Telephone Service Co., “the requisite level of creativity is extremely low; even a slight amount will suffice. The vast majority of works make the grade quite easily, as they possess some creative spark, ‘no matter how crude, humble or obvious’ it might be.”[20] Despite this low bar, it remains possible that AI-generated content could infringe upon human generated content, but not have sufficient human authorship to be copyrightable itself. This paradox will likely become more significant as humans develop custom models trained on their own artistic style.
Conclusion
While generative AI may harm creators if abused, it also has the capacity to transform creative workflows and empower individual content creators to compete against large studios[21]. Addressing AI-related copyright infringement requires a two-part solution. First, a centralized system should be established to streamline the process through which AI developers can obtain permission to use copyrighted works. Technology companies such as Meta have attempted to license content legally, but the fragmented nature of content ownership makes obtaining these licenses impractical. Second, AI companies should improve guardrails to ensure copyrighted content is not distributed to users. The growth of generative AI models should not come at the expense of the creators it is meant to empower. By adapting the existing system to enhance protections for creators’ rights, we can ensure that content creators and generative AI models peacefully coexist and even create meaningful synergies that positively affect creative markets.
References And Legal Authorities
- Stanford Institute for Human-Centered Artificial Intelligence, Artificial Intelligence Index Report 2026; see also Stanford HAI, “Inside the AI Index: 12 Takeaways from the 2026 Report”. Return
- Act 927 of 2025, codified at Ark. Code Ann. section 18-4-101(a)(1) (2025). Return
- Zhenya Ji & Ming Jiang, “A systematic review of electricity demand for large language models: evaluations, challenges, and solutions,” Renewable and Sustainable Energy Reviews, Vol. 225, 116159 (2026), https://doi.org/10.1016/j.rser.2025.116159. Return
- Kadrey v. Meta Platforms, Inc., No. 3:23-cv-03417-VC, slip op. at 8-9 (N.D. Cal. June 25, 2025). Return
- Folsom v. Marsh, 9 F. Cas. 342 (C.C.D. Mass. 1841); 17 U.S.C. section 107. Return
- Bartz v. Anthropic PBC, No. 3:24-cv-05417-WHA, Order on Fair Use at 28 (N.D. Cal. June 23, 2025). Return
- Kadrey, slip op. at 2. Return
- Kadrey, slip op. at 11-12, 26-27. Return
- Kadrey, slip op. at 28-34. Return
- Imke Reimers & Joel Waldfogel, “AI and the Quantity and Quality of Creative Products: Have LLMs Boosted Creation of Valuable Books?” National Bureau of Economic Research, Working Paper No. 34777 (2026). Return
- Reimers & Waldfogel, “AI and the Quantity and Quality of Creative Products” at 27. Return
- Andersen v. Stability AI Ltd., No. 3:23-cv-00201-WHO, Order on Motions to Dismiss and Strike at 12 (N.D. Cal. Oct. 30, 2023). Return
- Sarah Andersen, “The Alt-Right Manipulated My Comic. Then A.I. Claimed It,” The New York Times (Dec. 31, 2022); see also NYU Journal of Intellectual Property and Entertainment Law, “Andersen v. Stability AI: The Landmark Case Unpacking the Copyright Risks of AI Image Generators”. Return
- Poseidon Wave Media LLC v. Suno, Inc., No. 1:26-cv-03921, Complaint paragraphs 13, 24, 46-49 (S.D.N.Y. May 12, 2026). Return
- Poseidon Wave Media, Complaint paragraph 33. Return
- Dow Jones & Co. v. Perplexity AI, Inc., No. 1:24-cv-07984-KPF, Second Amended Complaint paragraphs 1-4, 51-54 (S.D.N.Y. Jan. 28, 2025); see also Opinion and Order denying Perplexity’s motion to dismiss or transfer (S.D.N.Y. Aug. 21, 2025). Return
- Trishla Ostwal, “Google’s Gen AI Search Threatens Publishers With $2B Annual Ad Revenue Loss,” Adweek (Mar. 14, 2024). Return
- Liz Reid, “AI in Search: Driving More Queries and Higher Quality Clicks,” The Keyword (Aug. 6, 2025). Return
- Thaler v. Perlmutter, No. 22-1564, Memorandum Opinion (D.D.C. Aug. 18, 2023). Return
- Feist Publications, Inc. v. Rural Telephone Service Co., 499 U.S. 340, 345 (1991). Return
- Andrew Cha, “87 Percent of Creators Say Creative AI Is Growing Their Business and Audience, According to Adobe’s 2026 Creators’ Toolkit Report,” Adobe Newsroom (June 16, 2026), adobe.com. Return